

工业大数据的来源
工业大数据来源主要有三个方面:一是企业经营管理数据;一是机器设备数据;一是来源于企业外部数据。工业大数据具有4V特性,即具有大量化(Volume)、多样化(Variety)、快速化(Velocity)、价值密度低(Value)。工业大数据可以分为结构化、半结构化或非结构化等几种类型;
工业大数据采集后需要经过数据ETL的数据处理过程,即数据的抽取(Extract)、数据的清洗(Cleaning)、数字的转换(Transform)、数字的装载(Load)。
大数据预处理(ETL)流程
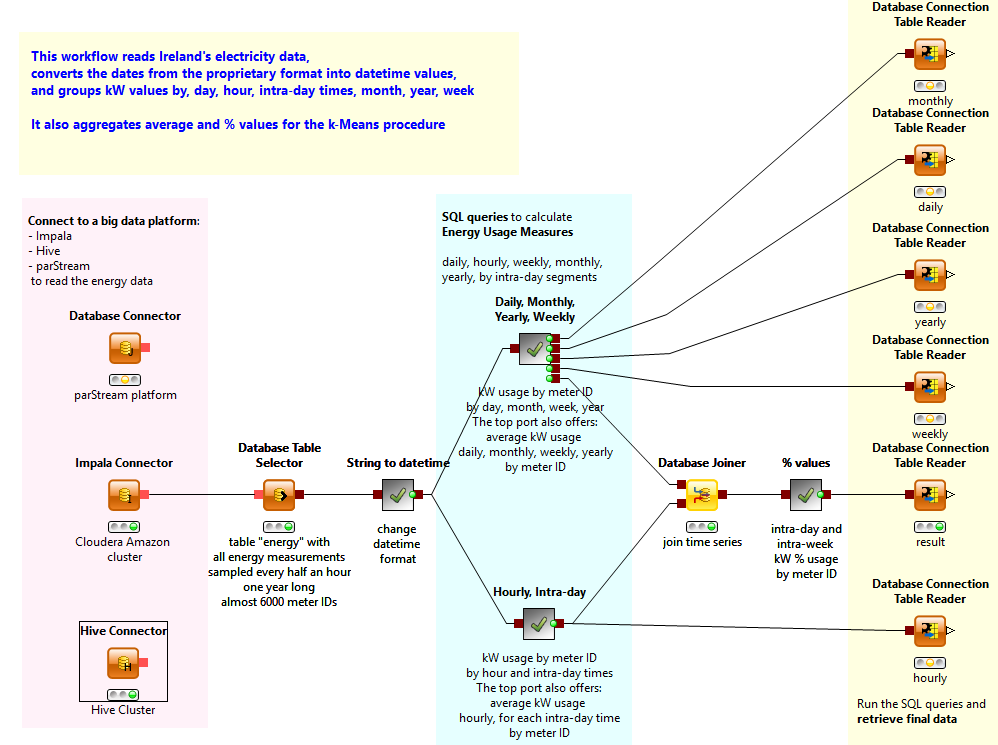
大数据存储计算平台简介
大数据平台能处理海量的结构化数据,同时还需要处理非结构化数据。为了满足当前及未来数据存储处理能力的需求,我们采用先进的“Hadoop+MPP”混合架构构建整个存储计算层。MPP平台主要用于处理海量高价值密度的结构化数据,Hadoop平台主要用于处理其他非结构化数据及低价值密度的结构化数据。同时整个大数据存储计算层对MPP数据库集群和Hadoop平台实现了融合,整合了列存储、智能索引、多副本、Mapreduce、Hive等大数据处理技术,并提供统一的管理能力。
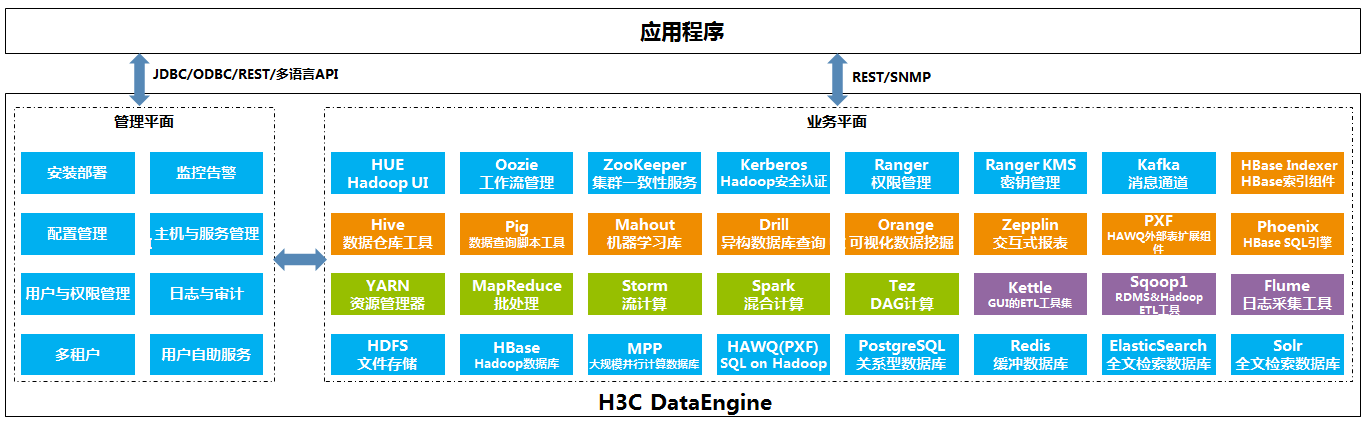
数据存储计算层
大数据平台能够解决传统数据平台面向海量PB级数据存储能力的不足,提供高性价的处理结构化,非结构化数据,根据业务场景不同灵活支持不同的 Hadoop+Spark 服务,MPP 分布式数据库服务,关系型数据库服务,内存计算服务,实时流计算服务,NoSQL 数据库服务等基础大数据和数据库服务,能根据不同场景提供物理多租或者逻辑多租的数据存储服务,为进一步的数据挖掘,业务深度分析打下基础。
大数据资源池为用户提供一套完整的大数据平台解决方案,包括数据采集交换、存储资源整合、数据加工处理以及数据增值服务等全系列功能,帮助用户构建大数据处理系统;支持多源的数据集成,将不同业务系统中分散、零乱、标准不统一的各种源数据中的数据进行汇聚。支持从DBMS、互联网、物联网、企业生产系统等各种数据源中提取数据,且由一个统一的操作接口封装,经过无代码的可视化配置后,可实现自动化地、分布式地执行整个ETL作业流程;提供交互式SQL和可编程API数据服务接口,主要包括SQL接口、MapReduce/Spark/Storm计算接口等多种可编程API、全文实时搜索接口、业务定向接口、关联查询接口,满足数据查询、可视化数据展示、数据交换、数据分析、目录服务、综合查询等业务应用的需要;提供Web图形化界面对集群可视化运维管理,并提供集群快速安装部署、机架展示、用户权限管理、主机与服务管理、监控及告警通知等功能。
大数据资源池采用Hadoop+MPP混搭的的计算框架为大数据基础平台,并结合数据采集、共享交换、数据服务运营等为用户提供一套完整的大数据底层资源池,帮助用户构建海量数据处理体系。
1) 逻辑架构
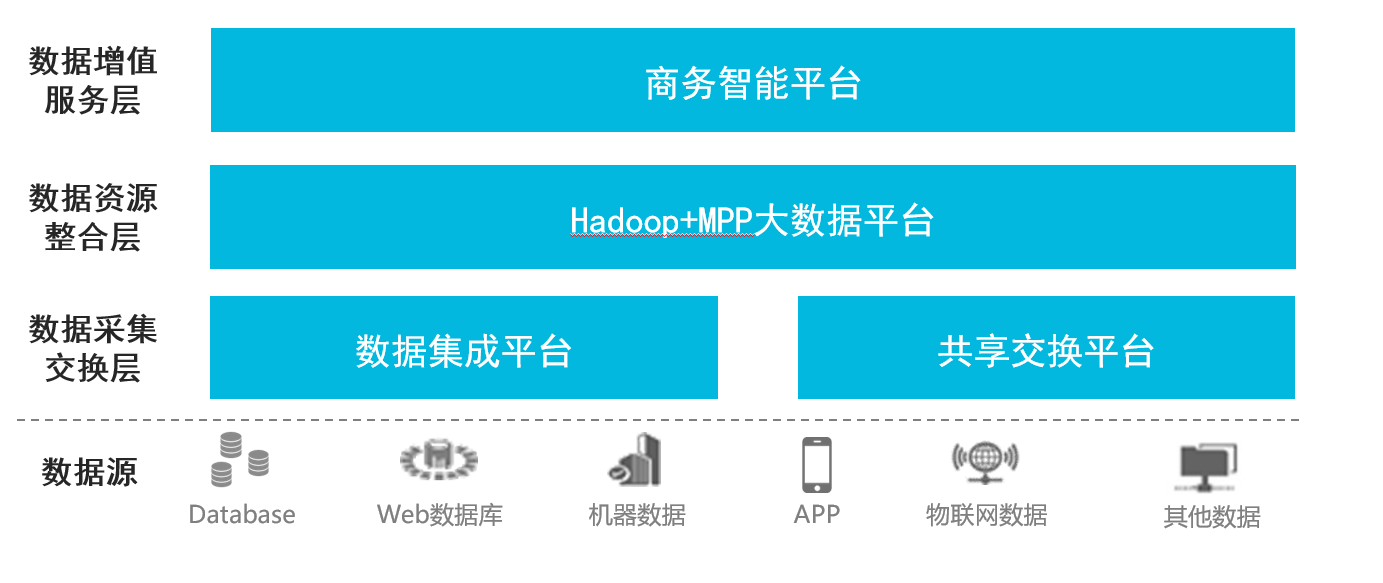
大数据资源池逻辑架构
2) 物理架构
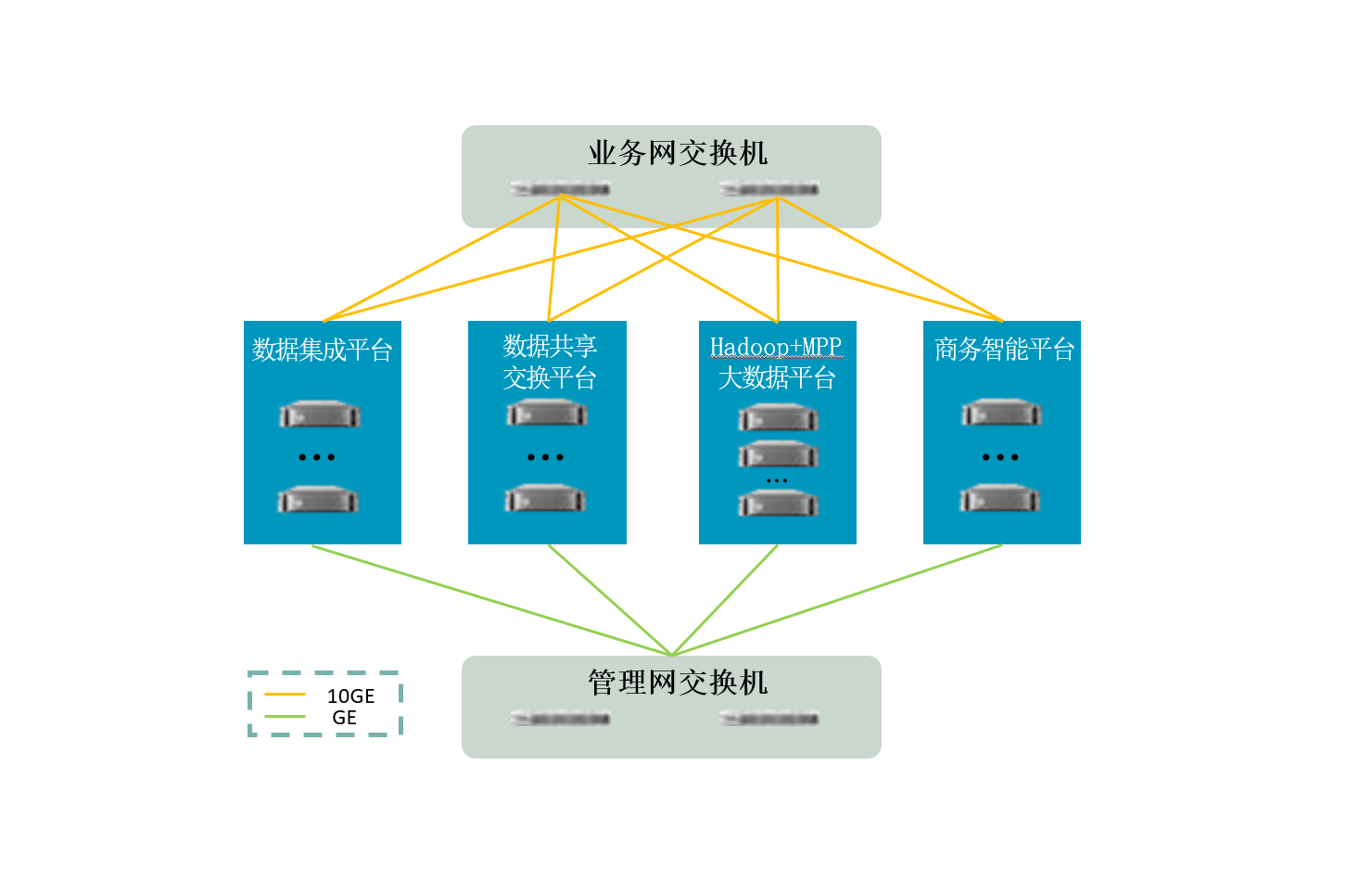
大数据资源池物理架构
产品优势:
- 存储处理海量工业大数据
- 为不同应用场景灵活提供不同的大数据服务
- 提供Web图形化界面对集群可视化运维管理


